Summary
Construction of speech applications such as text to speech and speech recognition requires a phonetically balanced speech database in order to obtain a natural output. We aimed to develop a corpora that could be useful in many linguistic and speech processing research.
Details
Typically, speech corpus contains high-quality recordings of a professional speaker’s voice. The aim of this work is to label the audio and text with time-aligned phonetic that can be used to analyze speech. Currently, the developed corpus contains 106860 words. It covers wide variety of domains including weekly magazine, novel, blog, legal data, parts of the constitution of Bangladesh, history, and different types of news.
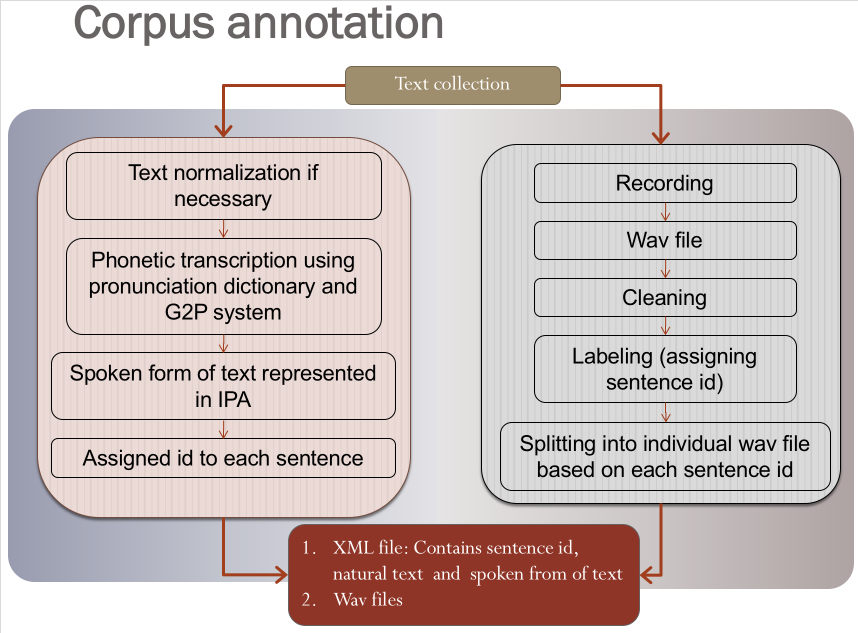
A professional speaker was selected for the voice and recorded in a professional voice recording studio. Recording of speech was completed in July 2008. After cleaning the recorded audio, the sentences are labeled with the text then words and phoneme label. This speech corpus can be used to develop acoustic models for speech recognition, to analyze the intonation pattern, and to develop a TTS by unite selection technique.
Please get the data from mendeley
OR
Please check the git project: Bangla-Speech-Corpora