Summary
This projects aims to develop an Optical Character Recognizer that can recognize Bangla Scripts. The entire OCR research and development task is mainly divided into three major parts: preprocessing, classification and post-processing. We performed experiment with several techniques for each individual parts and choose the appropriate methods in our implementation. Currently we are using Tesseract OCR engine to perform the recognition task.
Details
BanglaOCR is the Optical Character Recognizer for Bangla Script. It takes scanned images of a printed page or document as input and converts them into editable Unicode text. The current version of BanglaOCR deals will several independent parts as listed below.
- Preprocessing
- Classification
- Post-processing
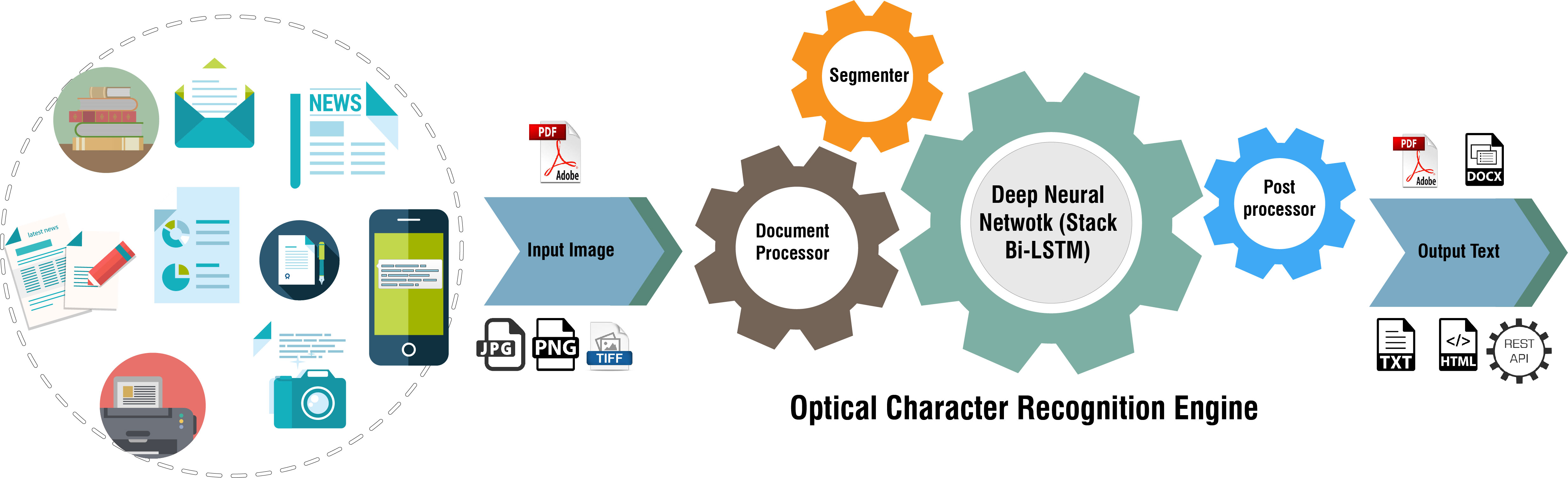
The Preprocessing task involves image acquisition, binarization, noise elimination, skew detection and correction, line, word and character level segmentation. Bangla Character segmentation is one of the most significant challenges. For classification we are using Tesseract OCR engine (one of the most accurate free software OCR engines currently available). To perform the post processing task we are using two levels processing. At the first level we are correcting the recognition mistakes based on a certain number of rules. At the second level we are using a suggestion based spell checker that is capable to identify the erroneous words and produce suggestions. The project goal of BanglaOCR is to develop a market place standard multilingual OCR system that will be capable to perform the digitization of a wide domain of Bangla Document images. This will help to archive the documents from all spheres and prevent the damage and lost of valuable documents and books.