Summary
Speech Synthesis is the artificial production of human speech. A Text-to-speech system converts normal text to speech. For many applications, it is important to develop a natural sounding Bangla Text to Speech. One of the major research areas for us to enrich the resources for Bangla Text to Speech and develop natural sounding synthesized speech.
Details
Speech is one of the most vital forms of communication in our everyday life. Since speech is a primary mode of communication among human beings, it is natural for people to expect to be able to carry out spoken dialogue with computers. This involves the integration of speech technology and language technology. Speech synthesis is the automatic generation of artificial speech signal by the computer.
Developing TTS involves the integration of speech technology and language technology. In the first phase the project team works on Language technology such as phonetic and phonological study on Bangla language. Since acoustic analysis on Bangla language has not done yet properly, so in the first phase project team working on this crucial job by coordinating. The second phase of this project is NLP (Natural Language Processing) where much of the implementation of this project involves. Implementation includes text normalization, IPA conversion, algorithm of syllabification, stress sound change rule and diphone generation module. The final phase of TTS is the phonetic modul, those include lexicon development, diphone identification, recording and splitting diphone.
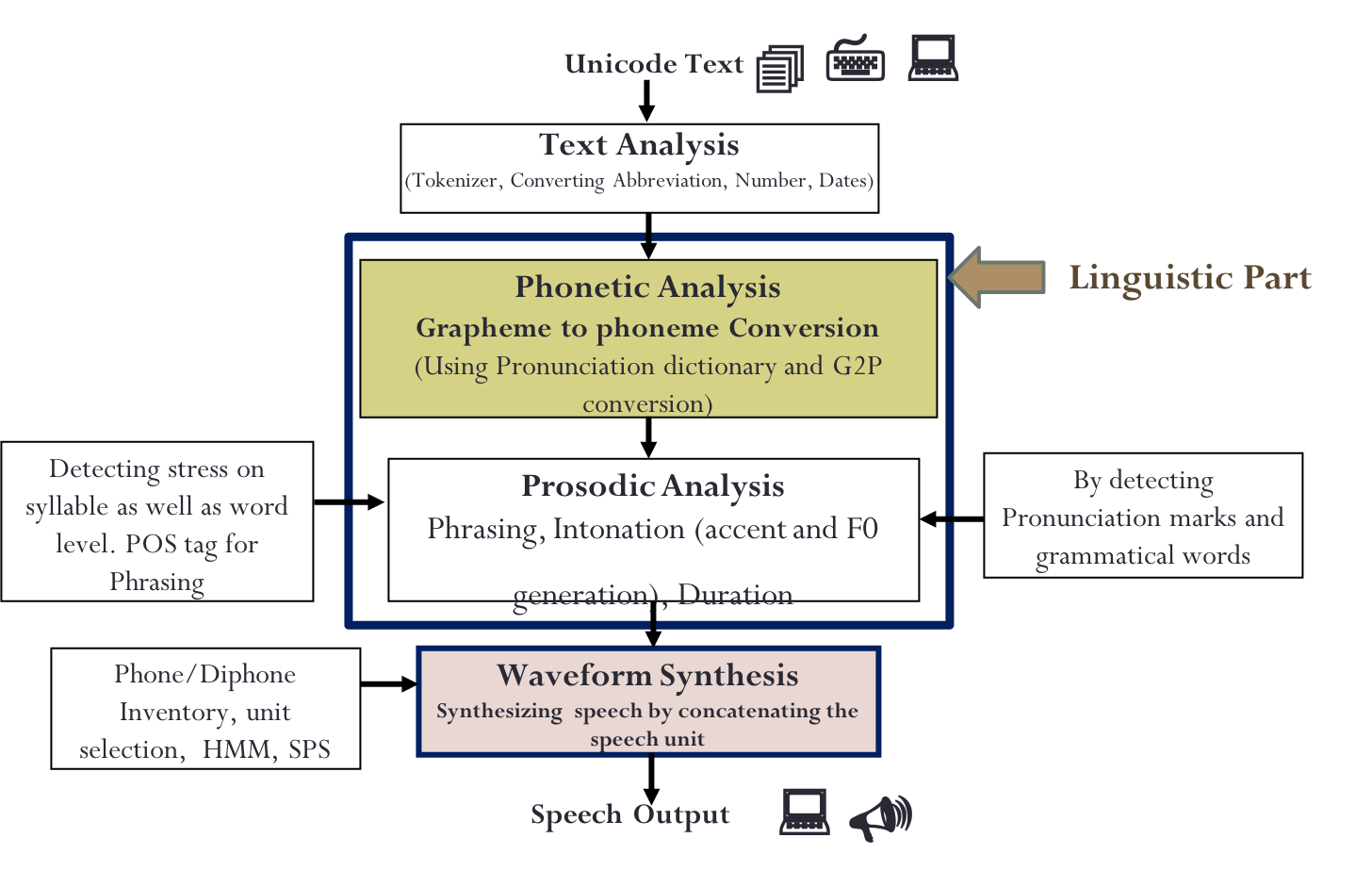
Text To Speech (TTS) system for Bangla language can be overcome the human-computer interaction, help to overcome the literacy barrier of common mass, can also empower the visually impaired population and increase the possibilities of improved man-machine interaction through on-line newspaper reading from Internet and enhancing other information system.
Different Modules of TTS Project
Phoneme inventory: A defined set of phoneme inventory is important for a language. This is not only important for phonetic analysis but also important for speech processing application such as TTS and ASR. There have been several studies in the past, mostly based on articulatory phonetics. We concentrated on the acoustic characteristics of Bangla phonemes, obtained by analyzing the recordings of male and female voices. The goal of this task was to determine the total number of phonemes and their acoustic properties in Bangla language. For this purpose, we collected text in different format and then recorded the text. We hired gender equivalent professional and non-professional speakers and recording studio for recording. Then acoustic analysis was done on the recorded speech. Finally, we concluded with 30 consonants, 14 vowels, and 21 diphthongs. [paper] [Speech data for analysis will be available soon]
Text Normalization: We have developed rule based text normalization system in two different technologies such as java and festival scheme. The job of text normalize system is to convert non-standard word representation to standard form. Currently this system can handle number, phone number, ordinal, cardinal, acronym, and abbreviation. [paper accepted for poster presentation in CLT09][Outputs will be appear soon]
Grapheme to Phoneme/Letter to sound system/ pronunciation lexicon: Our team developed a rule based pronunciation generator for Bangla words. It takes a word and finds the pronunciations for the graphemes of the word. A grapheme is a unit in writing that cannot be analyzed into smaller components. Resolving the pronunciation of a polyphone grapheme (i.e. a grapheme that generates more than one phoneme) is the major hurdle that the Automated Pronunciation Generator (APG) encounters. Bangla is partially phonetic in nature, thus we can define rules to handle most of the cases. Besides, up till now we lack a balanced corpus which could be used for a statistical pronunciation generator. This system is extending day by day to make the accuracy up to the mark. [paper] [Tools: Version-1.0, Version-2.0: coming soon]
Intonation Modeling: In linguistics, intonation is a variation of pitch while speaking which is not used to distinguish words. Intonation and stress are two main elements of linguistic prosody. Since, we do not have existing system for intonation in Bangla, so we are trying to make an intonation model using statistical system from speech corpus. We are manually labeling speech for intonation model at the sentence level.
Diphone database for TTS: Developed a diphone database consisting 4355 diphones. Diphone is the number of square of phones. We identified 30 consonants, 14 vowels and 21 diphthong phonemes. This includes designing nonsense sentences from diphone list, recording by professional speaker, splitting and labeling.
Katha: Bangla Text to Speech is a software package for the Bangla language which can help to tackle the illiteracy problem, empower the visually impaired and increase the possibilities of improved human-machine interaction. This project aimed to develop a TTS system for Bangla using diphone and unit selection concatenation techniques based on the Festival speech synthesis technology paper.
The Katha Bangla Text to Speech has been developed during the time 2007-2011, at CRBLP (currently does not exist), BRAC University. Due to the lack resources, the support has been discontinued. As a part of the research team, we are maintaining this project and hosted on github (previously hosted on sourceforge). The goal is make it publicly available for it’s wider research uses. From the begining of 2017, Cognitive Insight Limited has been providing a continuous support to extend its research work.
Please check the git project: Katha-Bangla-TTS